In our last blog post, we looked at a paper that used a small sticker (a "patch") to make any object appear to be a toaster to image recognition models. This is known as a misclassification attack -- the model still recognizes that there is an object there, but fails to correctly identify what kind of object.
In the paper, the authors show an example of misclassifying a bunch of bananas as a toaster, but you can use this kind of attack with anything -- for example, making a coffee mug look like a bird.

But you might not want to misclassify a coffee mug -- you might want to make it disappear. This is called an evasion attack, and to understand why it works, it helps to know a little bit about how most object detection algorithms work.
Models for object detection take as input a rectangle, and have to identify three things:
- is there something in this photograph; and,
- if yes, where is it located in the photograph; and,
- what kind of thing is it.
Step 2 can be thought of as a smaller image, like a crop of the original photograph, that contains only one object. Finding this smaller image in the larger one is nontrivial, because the number of potential locations grows exponentially with the size of the image. If your original photograph is 2 pixels by 2 pixels, there are 5 possible locations. If your photograph is 3 pixels by 3 pixels, there are 32 possible locations. Most photographs are more than 1000x1000, so this becomes unwieldy very quickly.
So, in practice, object detection algorithms tend to do one of three things:
- classify each pixel individually, then group them together into objects; or,
- use a simple model to generate a small number of proposed locations, then a complex model to classify them; or,
- use a small, fixed grid of proposed object centers, and have the model learn if there is in an object there, and if so, how large it is and what kind of object it is.
Here's an example of that third strategy, from Joe Reddy's description of the You Only Look Once (YOLO) algorithm:

In evasion attacks then, our goal is to make something look less like a bounded object -- which means specifically attacking these proposed object location steps.
In "Fooling automated surveillance cameras", Thys, Van Ranst, and Goedemé do this with adversarial patches. The training strategy is pretty similar to the strategy for the adversarial sticker: we take a blank patch, paste it on top of the image we are attacking, then tweak the pixels in our patch one by one until we get our desired effect. Just like the patches paper, we're going to apply random rotations, resizing, and color changes to make sure our attack is robust in the real world. The main difference is that instead of trying to maximize the probability that the image looks like a toaster, we're going to minimize the probability that it looks like anything at all.
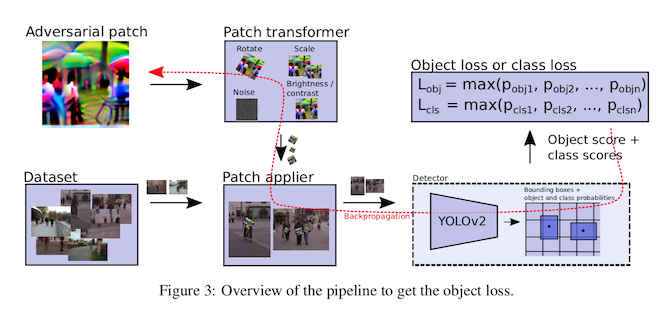
This results in a patch with an attack success rate (ASR) of about 75%. This means that, for images where a model had correctly found a person in the original image, it only does so in the attacked image 25% of the time.

Now, you'll notice in the example photographs, that this patch is printed on a piece of cardboard that the experimenters are holding up in front of them. This is because (a) the patch is quite large -- larger than the experimenters' torsos; and, (b) the patch has to stay perfectly flat to be effective. Additionally, the patch isn't very robust to displacement, so not only do you need to hold it, it has to be directly between you and the camera. This makes it a bit unpractical to use in real life, which we'll talk about in a future blog post.
For now, we'll review one more interesting aspect of the paper. We mentioned above that object detection algorithms tend to have separate steps for finding an object, and then deciding what that object is. In this papers, the authors try attacking each step individually, and then both at once. Here are examples of what those different kinds of attacks look like:

You should notice that attacking just the classification -- is this object a person or not -- produces a patch that basically looks like a green blob. This is a typical visual characteristic of an unsuccessful attack; it looks poorly defined because the attack algorithm struggled to make any headway against the model.
By contrast, the attacks on the location -- is there an object here or not -- are visually distinctive. If you squint, one of them looks like an outdoor plaza, with people sitting at tables covered by umbrellas. This makes intuitive sense -- most objects do not have plazas in the middle of them.
The others look like a teddy bear and a bunch of kites, maybe? These two are also trying to minimize the classification score, which may be making the attack harder to pull off.
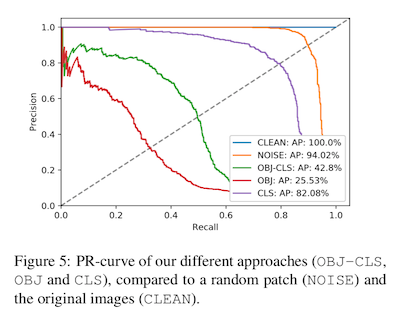
The success of these attacks follows the visual distinctiveness. The best attack success rate goes to the strategy of just minimizing the objectness (the plaza, which we see in red). The next best goes to attacking both object and class at the same time (the kites, in green). The least effective strategy was in attacking the classification accuracy (the greennblob, shown in purple in the graph).
These authors are applying this evasion attack to people, but it can be applied to any other kind of object. Here, for example, is an evasion attack applied to a coffee mug:

which you can find here.
This blog post first appeared on adversarial-designs.
S. Thys, W. Van Ranst, and T. Goedemé, “Fooling automated surveillance cameras: adversarial patches to attack person detection”. Available: http://arxiv.org/abs/1904.08653