In our last blog post, we talked about how small perturbations in an image can cause an object detection algorithm to misclassify it. This can be a useful and sneaky way to disguise the contents of an image in scenarios where you have taken a digital photograph, and have the chance to modify it before sending it along to the algorithm you hope to trick.
But what if someone else takes the photo?
Adding small changes to the image pixels won't work, since you don't have the digital copy -- you can only modify the real world. You could try adding the same small changes to some real life object, but:
- you won't be able to modify the entire photo -- only one small part of it; and,
- you can't control for lighting or other kinds of camera noise; and,
- you have no idea what the frame or orientation of the photo will be.
To put it another way, if you add a tiny, subtle change to a coffee mug that you want to look like a dog, you risk that tiny, subtle change being completely obscured by a shadow or some lint on the camera lens.
So, to make an adversarial image attack work well in real life, you'll need to make a large change to a small area of a photo, that is robust to changes in lighting and orientation.
This is exactly what Brown et al. do in their 2017 NeurIPS paper, "Adversarial Patch".1
Instead of allowing their training algorithm to change any pixel in the original photograph a little bit, the authors tell the algorithm to change any pixel as much as it wants, but in a separate, smaller image. That smaller image is then applied to a random location in the original photograph, and the orientation is varied randomly as well:

The end result is a sticker, which you can place next (or on!) ordinary objects, to cause them to be misclassified. You can order one of these stickers for yourself here.
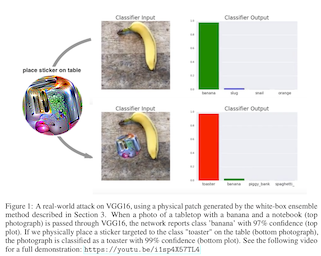
What makes this a little bit tricky is that you need access to a model that is capable of doing this kind of object recognition. Researchers call this a "white box attack", because you can see inside of the thing you are trying to fool. This is in contrast with a "black box attack", where you have to make guesses and assumptions about the algorithm that you are trying to fool.
The authors have access to a number of object detection algorithms, but they don't know which one will end up being used in the real world by someone else. Somebody might take a photo of their sticker with a new object detection model that they've never heard of! To head off this possibility, the authors go one step further and use several different image classification algorithms at the same time to create the adversarial patch. The logic goes something like this: if the sticker works well on several different existing models (white box), it is likely to work well against future models too (black box).
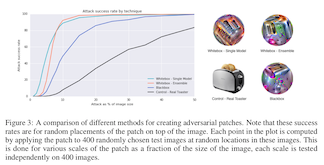
We can see that the sticker trained from several models (the "ensemble") looks visually different than a sticker just trained on one model. Hopefully this translates into a more effective attack against future kinds of models!
This blog post first appeared on adversarial-designs.
-
T. B. Brown, D. Mané, A. Roy, M. Abadi, and J. Gilmer, “Adversarial Patch,” arXiv:1712.09665 [cs] Available: http://arxiv.org/abs/1712.09665 ↩