Last time, we talked about data poisoning attacks on machine learning models. These are a specific kind of adversarial attack where the training data for a model are modified to make the model's behavior at inference time change in a desired way. One goal might be to reduce the overall accuracy of the model, and these are called availability attacks. Another goal might be to cause the model to make a specific kind of misprediction, or to mispredict a specific input. These are called backdoor attacks.
The important (and cool) thing about data poisoning attacks is that they attack the model when it is easiest -- during collection of training data -- and don't require an attacker to have access to the model, the test samples, or even the rest of the training data. Seeding a model with poisoned training data could be as simple as uploading it to a public photo sharing website.
This is in contrast to inference-time adversarial attacks, which require modifying the test samples, which requires either:
- intervening in the data processing pipeline after data are collected but before the model sees them (very hard); or,
- creating attacks which are robust to real world perturbations, like lighting changes and occlusions (also very hard).
However, in "poisoning deep learning algorithms", we saw that generating data poisoning inputs had challenges of its own. In particular, doing this was computationally expensive, for two reasons:
- because we have a dual optimization problem -- we are training our poisoning strategy at the same time we are training a model; and,
- because calculating the gradient on the model weights with respect to the poison sample has to be estimated at each iteration.
To attempt to reduce this cost, we can think through what our attack is trying to achieve. Intuitively, we want to change a model's behavior such that samples which used to fall one side of a decision boundary end up falling on the other. We can try to achieve this by chaging where samples end up in the featurized space, or by shifting the position of the decision boundary. With this intuition in mind, we can think about a couple of simpler heuristics for creating a poisons.
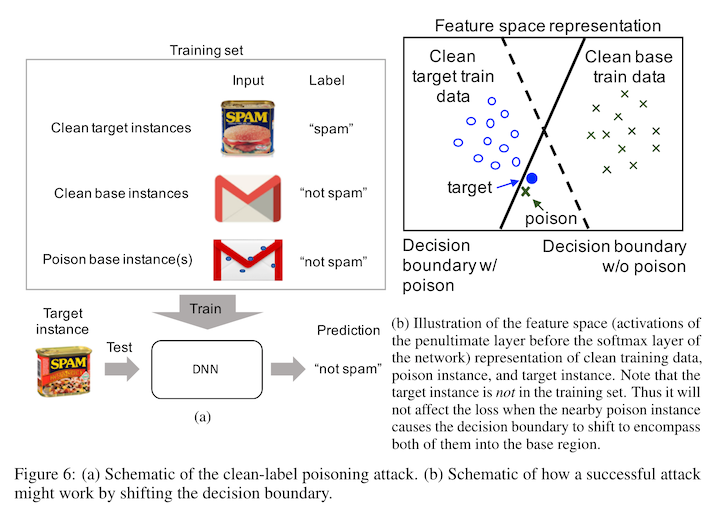
Let's say, for example, that we wanted to poison a model such that it misclassifies dogs as cats, but leaves the rest of the model's behavior totally unchanged. To do this, we would want to inject cats that looked dog-ish into the training data, such that the model sees dog-like features with the label "cat". This in theory will move the decision boundary for dogs closer to wherever the cat images end up in the feature space.
One way to do this is by intervening on the feature-ized representations of the images. In neural networks, we have access to these features directly, as the outputs of the last layer of the model that happens before the classification layer, so we can directly compare the model features for cats with the model features for dogs. What we can do then is create a optimization problem, where the loss is the distance between the feature space of a cat image and a dog image, then backpropagate that loss to the image of the cat, and change the image to have dog-ish model features.

Because we don't have to train the outer image classification model, we avoid problem 1, and computing a loss directly on the distance between to vectors is much easier and faster than estimating the gradient in problem 2, so we avoid that as well.
An even simpler way to do this is to intervene on the data space directly. To make a model see dog-ish features on a cat, you can overlay the image of the dog directly on top of the cat image! Now, you don't want to occlude the image of the cat, so you start by making the image of the dog mostly transparent, and then overlay it (this is called watermarking). It does carry a risk that if the opacity of your watermark is too high, it will be easy to tell that the image has been tampered with and your poisoned sample might be excluded from training.

So what does this look like in practice? Shafahi and colleagues at the University of Maryland undertook a study where they used both methods -- backpropagating feature representations and watermarking -- and compared their attack success rates.1
The feature representation attack worked well for transfer learning scenarios, where the feature extraction layers are downloaded in advance and only later layers are trained, ultimately achieving an attack success rate of 100%! However, if the other layers are allowed to change (e.g. you are training a model from scratch), the feature representation attack becomes much less successful. The authors don't provide an attack success rate for adding feature poisoned samples and training a model from scratch, but they imply that it is close to zero.
What the authors do show is that this attack failure is due to the model updating the feature extractor weights in such a way that the poison examples get shifted back to the correct side of the decision boundary -- undoing all our hard work!
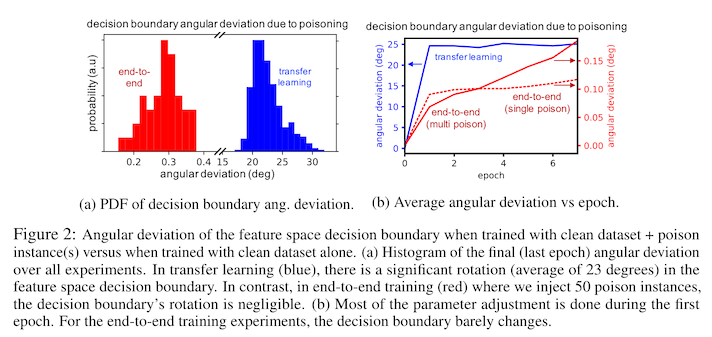
The watermarking approach in constrast is much more successful in the end-to-end training scenario, ultimately achieving attack success rates between 20% and 80%, depending on which class is being targeted.2 This is because the watermarking attack changes the learned featurization process, such that samples of dogs end up in similar locations in feature space as the samples of cats. In this scenario, the model can't compensate against the attack by learning to shift its decision boundary, and so the attack remains successful in the end-to-end training scenario.
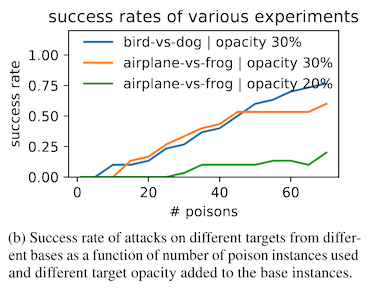
What we've seen here so far is a faster / cheaper way to create poisoned training samples, but those poisons apply to a whole class of images. That is to say, the model will always perform poorly on every dog, in an indiscriminate manner. Next time, we'll see how we can attack a model such that it only misclassifies things on demand, by using an adversarial trigger.
This blog post first appeared on adversarial-designs.
-
A. Shafahi et al., “Poison Frogs! Targeted Clean-Label Poisoning Attacks on Neural Networks,” arXiv:1804.00792 [cs, stat], Nov. 2018. Available: http://arxiv.org/abs/1804.00792 ↩
-
It is much easier to e.g. make a model mispredict a dog as a cat than it is to make a model confuse dogs and airplanes, because dogs and cats will already be closer in the feature space. ↩