In the last blog post, we saw that a large carboard cutout with a distinctive, printed design could help a person evade detection from automated surveillance systems. As we noted, this attack had a few drawbacks -- largely, that the design needed to be held in front of the person's body.
It's inconvenient to walk around holding a printed sign at all times. What if you wanted to open a door, or drink some water? Lucky for us, people walk around with printable surfaces on them all the time: their clothing. What if we could print an attack on the clothes that someone is wearing?
In practice, this is trickier than it sounds, because -- unlike a cardboard signs -- clothes are not rigid. This means that the design seen by the cameras you are trying to evade will drape over the shape of your body, with folds in the fabric that emphasize some parts of the design and hide others. To make matters worse, the way your clothes hang on your body changes as you move!
And, as a general rule, these designs are not robust to wrinkles, so naïvely taking the printout from the previous paper and putting it on a shirt will result in an attack success rate (ASR) much lower than what was experimentally reported.
So what we require is a way to model the movement of the fabric during the design of the patch. Specifically, we want to be able to generate a design that has a good attack success rate from the camera's perspective, then warp it such that the fabric movement will reproduce the successful design when it's on someone's body.
In "Evading real-time person detectors by adversarial t-shirt", Xu et al. do a side-by-side comparison of these two options: rigid surface attack (which they call "baseline"), and fabric-ready attack (which they call, at different points in the paper, either the "TPS transform" or "our method").
They start with some nice pictorial representations of the different success of these two methods on a video of two people walking down a hallway. You can see that the baseline method is consistently recognized as a person (with a confidence threshold of 70%), whereas the TPS method mostly fails to be detected, although some frames still show that a person is there.

Now this sounds pretty simple, but we haven't talked about how the fabric folding is incorporated into the attack training. This is a really hard thing to do! Computer animation studios like Pixar spent decades building physics-based algorithms to model the movement of deformable objects like clothes or hair. They got really good at it! But we'd rather not build an animation studio in our journey to make a t-shirt.
So the authors do something particularly clever. They print a grid on a t-shirt, and record one of the experimenters wearing it while walking down a hallway. Then, they take each frame of the video, and write an equation that goes from the flat, rigid grid, to the warped grid on the experimenter's body. When they train the attack, at each iteration of the training algorith, they project the adversarial patch backwards through one of those equations, to get a rectangular, printable patch, that will be a successful attack when it is warped by being draped over the experimenter's body.

But where do those equations come from? There is a well-described set of transformations that you can apply to an image to rotate it, or stretch it, or change its size. These are called affine transforms, and they're what your phone uses to do things like stitch individual photos together to make a panorama. These unfortunately won't quite work for the fabric warping, because they apply to the whole image -- if one corner gets rotated, the whole image gets rotated.
This isn't quite how fabric works. So the authors use thin plate spline (TPS) mapping, which adds new terms to the equation that allow one part of the image to move a small distance in any x,y direction independtly of the other parts of the image. This lets you have a wrinkle on one side of the shirt without moving the entire shirt around in space.
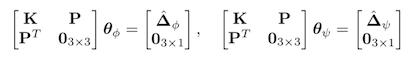
The results show that adding this additional transform improves the attack success rate from about 30% to about 60% -- this is a big improvement! Before we get too excited about this though, it's important to note one detail from the methods section of the paper. The training examples that they used are videos of the experimenters walking down a hallway. The tests they conduct are on those same experimenters walking down that same hallway.
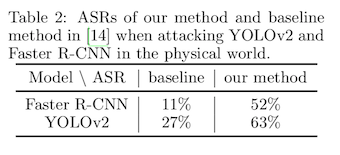
So this attack success rate could be lower for other people, or for in people in different hallways, or for people not in a hallway.
This warping strategy is still a good idea though, so it's what we use when generating adversarial attacks -- even on rigid objects like coffee mugs or water bottles! Here's an example of what one of the learned transformation looks like for a coffee mug:

What's particularly nice about this is it lets us model realistic views of each object: for example, the way the bottom corners of the mug aren't visible when you are looking at it from above. In the original adversarial patch paper, the authors apply transformations like rotating the whole image, or making it all darker, in an effort to make the patches more robust to real life camera noise. But applying learned transforms like perspective shifts during the attack training ensures that we get adversarial attacks that are as effective as possible when deployed in the real world.
This blog post first appeared on adversarial-designs.
K. Xu et al., “Evading Real-Time Person Detectors by Adversarial T-shirt,” arXiv:1910.11099 [cs], Oct. 2019.