In the recent posts where we have been discussing data poisoning, we have mostly been focused on one of two things:
- an availability attack, where we degrade the accuracy of a model if it gets trained on any data that we generated; or,
- a backdoor attack, where the model performance remains unchanged, but we gain the ability to alter its predictions after it has been deployed.
There was one kind of backdoor attack that used a similar method to other computationally inexpensive attacks -- adversarial watermarking -- but with a different end goal in mind. Instead of causing a model to misbehave in real life to evade identity detection or object recognition methods, it was concerned with making it easy to discover whether a model was trained on your data in particular. The insight was that you could use the success of backdoor attacks, which are effective even if only a small fraction of the training data is watermarked, as evidence that a model saw some data that it shouldn't have, e.g. because you didn't consent to have it used as someone else's training data.
You can think about this as being similar to a membership inference attack, but instead of trying to recover the values in the training data, we are only concerned with whether a known example was present during model training (more on this in a future blog post!).
Besides privacy, this kind of attack can be useful for transmitting the watermark itself. Let's say, by way of example, that you have some information that you would like to keep secret from most people -- like your award-winning chile recipe -- but need to transmit to your brother for a competition. If you send it over email directly, you risk it being discoverable by the other cooks (and google, or whoever else your email provider might be) because emails aren't typically encrypted. You arent going to set up your own email server because that is madness -- so what can you do?
You can hide the recipe in the text of an otherwise normal-looking email wishing your brother good fortune in the competition. This method of transmitting secret information by hiding it inside innocuous information is known as steganography. There are a lot of ways that you could do this, but these methods all make tradeoffs in two directions:
- How easy will it be for someone to tell that there is a hidden message?
- Assuming that there is a hidden message, how easy will it be for someone to decode it?
At one extreme, you can think about writing out the recipe, then encrypting the whole thing, and dumping the encrypted message in the email. It might look something like this:
c49efdc592edaba0d7ccd4xe98ce0d412e2cfd2Se9
That might be very difficult to decode, but it's very easy for someone to tell that your message has something secret in it, so it fails at being not discoverable. At the other extreme, you can image writing out the recipe -- but then just sending it as is. It might look something like:
Dear brother,
Here is the totally normal and not secret thing you asked me to send.
This is easy to decode (because nothing has been hidden!), but it looks very normal, and so someone trawling through your emails looking for things that look like steganography would miss it completely.
Here's an example that is inbetween these two extremes. You could come up with a mapping from real words to code words like this
{
'and': 'apple',
'asked': 'banana',
'brother': 'coconut',
'dear': 'date',
'here': 'elderberry',
'is': 'fig',
'me': 'grape',
'normal': 'huckleberry',
'not': 'jackfruit',
'secret': 'kiwi',
'send': 'lime',
'the': 'mango',
'thing': 'nectarine',
'to': 'orange',
'totally': 'pineapple',
'you': 'raspberry'
}
use it to translate your message, so it looks like this:
Date coconut,
Elderberry fig mango pineapple huckleberry apple jackfruit kiwi nectarine raspberry banana grape orange lime.
and then send it. It is composed of real words, so it might make it past very simple automated filters, but if anyone is using letter counts, or word counts, or n-gram co-occurances, this message will look statistically fishy. If you only ever use this set of code words to send this one message, it is basically un-decodable. However, the more often you use it, the easier it will be for someone else to use the distributional properties of language to figure out what individual words are. Fig, jackfruit, mango, and orange will show up a lot, so those will be very easy to decode.
Ideally, you want a system that produces otherwise normal-looking emails (to avoid your message being detected), but also hides information in ways that are hard for a third party to retrieve (to avoid your secret message being decrypted).
In "Adversarial watermarking transformer: towards tracing text provenance with data hiding"1 Abdelnabi and Fritz propose using adversarial watermarking to do this. One key difference between their approach and the "Radioactive data" paper2 is that Abdelnabi and Fritz are not training a single watermark -- they want to be able to easily train many watermarks, or be able to hide lots of data.
The second key difference is the modality. Making an image watermark is pretty simple, because small changes to pixel values are hard for humans to detect, and also don't change the semantic value or meaning of the picture. If you add 1 to every pixel in a picture of a dog, it still looks just like a dog!
Watermarking in text is harder, because very small differences in the inputs cause large changes in their interpretation. Take the example email from before -- if we add 1 to every character (in ascii or unicode), the email becomes this:
Efbs!cspuifs,
Ifsf!jt!uif!upubmmz!opsnbm!boe!opu!tfdsfu!uijoh!zpv!btlfe!nf!up!tfoe.
Completely different! So we need to find ways of substituting individual words in the input that preserve the semantics of the original as much as possible, but are still recoverable by our brother who is becoming more and more impatient about getting that chile recipe. Here's an example of what this could look like, again using that same email:
Dear brother,
Here is the totally normal and not secret thing you told me to send.
Can you tell what is different without knowing the original sentence?
Here are some more examples from the Abdelnabi and Fritz, using their adversarial watermarking method:

You'll observe that most of the examples here are modifying things like prepositions, where an individual word can be substituted without changing the overall meaning of the sentence very much. So, for example, from might become of, or from might become with, depending on how the word was being used.
At this point, you might have a couple of questions. First, how can you make word substitutions with that kind of specificity? A table that lists out synonyms (like wordnet) is going to struggle to incorporate the context in which the word appears. Second, if the word substitutions are that hard to notice, wouldn't they also risk losing part of the information you want to send?
The answer to the first question is that the authors use a transformer, a sequence-to-sequence model, that is particularly good at learning where a word should appear, and in what context. These models are the current standard in Natural Language Processing (NLP) tasks like translating text between one language and another, specifically because they are good at incorporating local context into their expectations.
To be a little more specific, the encrypting or data-hiding architecture is a fairly standard transformer, but with two differences. First, instead of taking just a text input, it takes a normal text passage along with a secret message, encoded in binary (i.e. just 0s and 1s). Second, instead of trying to predict text in another language, it is trying to re-generate its own text input. This is called the reconstruction loss, and it helps the encoded message look similar to the original.
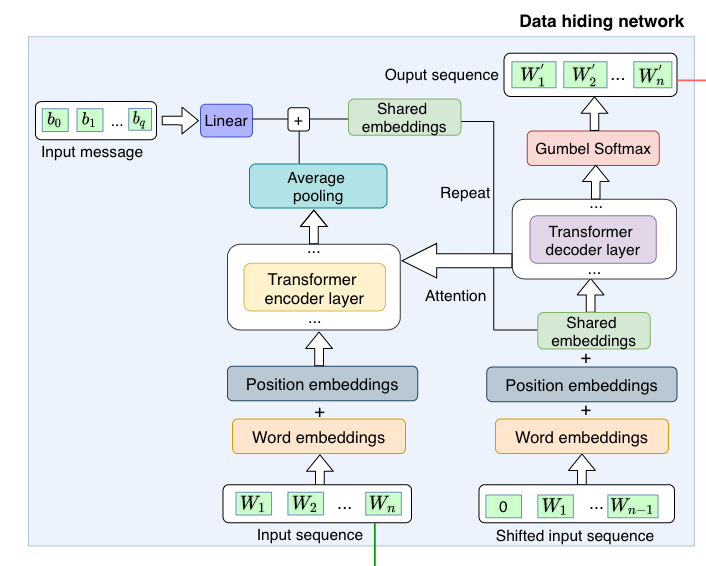
The decrypting or data-revealing network is another vanilla-ish transformer. It takes as input the output message from the encrypting network, but it is trained to predict just the binary inputs given to the encrypter. This is the fidelity loss, and it helps the model architecture learn to encrypt data such that it is easy to recover.
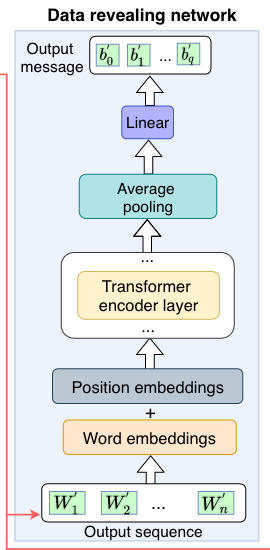
If these models were trained separately, the encrypter network would very quickly learn to ignore the binary message and copy its text input exactly, and the decrypter would never get a chance to learn how to recover a secret message. So instead, these models are trained together, so that the fidelity loss is balanced against the reconstruction loss. We're okay paying a small reconstruction loss (e.g. we modify the input sequence a little bit) if it means that we have good shot at recovering the binary signal.
If you use these two components alone, what you'll find is that the encoder learns to make a single, giant, obvious change to just one word in the input. Here's an example from the paper:

Because only one word has changed, the reconstruction loss is small. It's a very obvious change, so the fidelity loss is also small. We need one more step to this model, which is a discriminator.
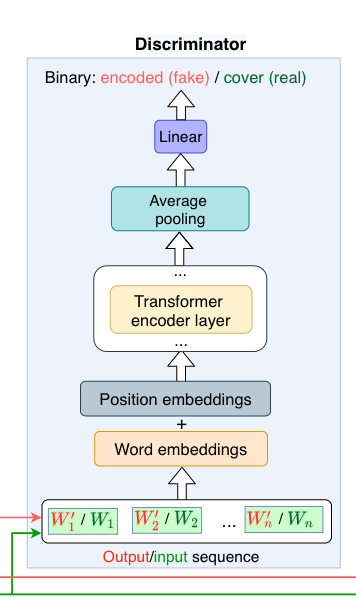
A discriminator is a model which takes two inputs -- one normal, one watermarked -- and it's job is to guess which input is the modified one. Whether another transformer can tell if you mucked about with the inputs is called the discrimination loss, and it helps the encrypter learn to make less obvious changes to the inputs.3
We still aren't quite there. If we look at the model outputs at this stage, we notice something a bit odd -- the encrypter is using markup tokens (like End Of Sentence <eos>) or other agrammatical changes to encode the binary message. These might not be very noticeable to a machine, but they do change the semantics of the modified inputs to a human reader.
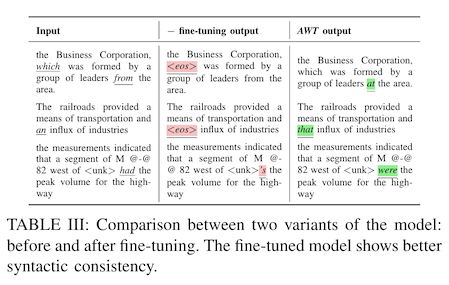
This is a fairly common problem in adversarial attacks -- it's why, for instance, adversarial attacks on images typically have limits on the total number of pixels they modify, or a limit on how much they can change an individual pixel value. In this case, since we're dealing with language, we need some sort of semantic distance that we can keep small. The authors use embedding distances for this (from an off-the-shelf language model), and add a fine-tuning step at the end of training where they add semantic distance to the other three loss terms, and train at a lower learning rate for a bit.
Okay, so that was one of your questions! The second question was about lossiness -- how likely am I to recover the correct binary message? The bad news is not very. The changes the encrypter makes to the inputs are subtle enough at this point that the decrypter sometimes misses a single bit 10-20% of the time.
Abdelnabi and Fritz have a pretty pragmatic solution to this -- repeat the message! If I need one sentence to encrypt my secret binary message, and my email has four sentences in it, I can transmit four copies and let my brother average over the decoded messages. Recipe intact!
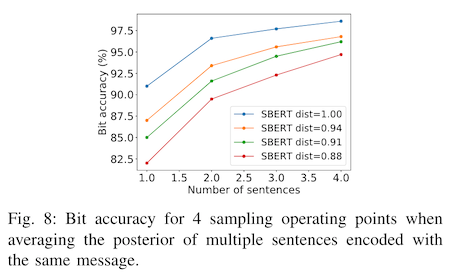
Now here's the bad news. In the examples in this paper, the authors are hiding 4 bits (e.g. 0011) in a text passage of 80 words. If you assume ascii encoding for the text inputs, and an average word length of five characters, you'll spend 800x more memory hiding your binary message than your message would occupy on its own!
Another way to think about this is that you will spend 1600 characters hiding a single secret character.
Another way to think about this is that this blog post is just long enough to hide the word steganography in it 🤔.
This blog post first appeared on adversarial-designs.
-
S. Abdelnabi and M. Fritz, “Adversarial Watermarking Transformer: Towards Tracing Text Provenance with Data Hiding,” arXiv:2009.03015 [cs], Sep. 2020. Available: http://arxiv.org/abs/2009.03015 ↩
-
A. Sablayrolles, M. Douze, C. Schmid, and H. Jégou, “Radioactive data: tracing through training,” arXiv:2002.00937 [cs, stat], Feb. 2020. Available: http://arxiv.org/abs/2002.00937 ↩
-
a quick note on vocabulary -- the authors refer to this model component as the adversary, since it competes with the encryption model, and it is used in the same sense as "generative adversarial network"; this is not the same sense of adversary in "adversarial attack", so we call this model component a discriminator in this post to avoid any confusion ↩