I spent a lot of time thinking about the title for this post. Way more than usual! So I hope you'll indulge me in quickly sharing two runners up:
- The real data posions were the adversarial examples we found along the way
- Your case and my case are the same case!! Adversarial examplesa are data poisons
Okay, with that out of the way --
For the last five months on adversarial-designs, we have been talking about data poisoning. This is a way of hacking someone else's machine learning model by manipulating the data used to train that model. We saw how you can use this to add a secret trigger to the model, which makes is malfunction only under certain special circumstances (like smiling! Robots have a hard time with this). We also saw how you can add a special watermark to your own personal data, so that you can tell if anyone has trained a machine learning model on it when they shouldn't have.
Both of these cases used a strategy called adversarial watermarking, where a semi-transparent pattern is layed on top of a regular old picture. If your watermarked picture is used to train a model, you gain some measure of control over this model (just you! You have to know what the watermark is).
The benefit of using watermarking is that it is cheap to do, computationally speaking. Creating data poisons the "real way" involves solving two simultaneous problems:
- an inner problem, where you train a model on data, and you want the model that understands the data the best; and;
- an outer problerm, where you train data on a model, and you want data that makes the model understand data the worst
The real problem here is that the kind of data that makes a model learn the wrong behavior early in its training process is not the kind of data that makes a model learn the wrong behavior later in its training process. If you try to explicitly solve the data poisoning objective, you'll find (mathematically) that you have to model the entire training process at once! For any nontrivial neural network, this is like asking a computer to do one month of work in one second.
So, in practice, data poisoning methods have centered around a few heuristics that let you solve a cheaper version of the original, expensive problem. One of these is watermarking, which is lovely in that it doesn't actually require any computation. We have talked about this here and here.
Another is gradient alignment, where you apply a small (in terms of pixel values) change to an image, to make its features look similar to an image of a very different thing. This is tricky because it requires that you (the attacker) have a good understanding of how your adversaries turn raw images into model features. We talked about this here.
Finally, instead of solving the full data poisoning objective, you can cheat a little bit by solving a smaller part of the objective. Concretely, instead of evaluating the model updates for all of the epochs across an entire dataset, you can model just the next n updates, where n < 10, and obtain a reasonable approximation to the full objective. We talked about this here.
But what if there was another way? What if you didn't need to unroll a computation graph at all?
Let's think about the problem this way. If you knew, in the best of all possible worlds, what was important about an image, it would be a lot easier to construct a data poison that leveraged this understanding about feature transformations. The motivation behind the gradient matching and the training unrolling strategies is that you can't know what is is useful to a model without looking inside the model at either its internal parameters or its gradient updates.
Or can't you?
We saw in our discussions of test-time attacks on machine learning models (just called adversarial attacks) that you could take an existing, pre-trained model and a few training examples, and use a technique like fast gradient sign method (FGSM) or projected gradient descent (PGD) that backpropagates a classification loss through the model back to the training example, and then tweaks the input toward a higher loss (instead of tweaking the model parameters toward a lower loss). Madry's work in particular1 demonstrated that these tweaked inputs have features that are useful to a model for classification, but are also not signals that human would rely on to make classification decisions.
Fowl et al. take this insight -- that adversarial examples uncover useful but brittle features -- and investigate whether these work as data poisoning inputs in Adversarial Examples Make Strong Poisons 2. Previous attempts had shown weak attack strength, but Fowl's attack is very successful, degrading the accuracy of a model trained on CIFAR from 95% down to 9% (note: this is with a poisoning budget of 100% poisoned training examples -- we'll come back to that in a minute).
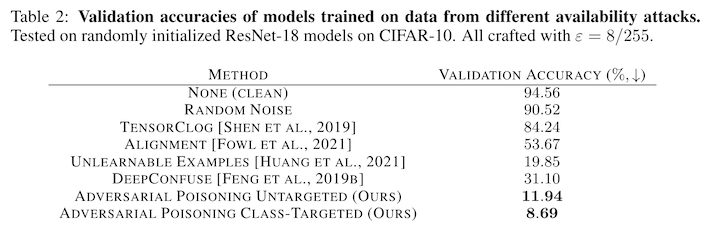
Why the difference in effectiveness? The authors point to two key innovations in their approach:
- they increase the number of steps used in crafting the adversarial perturbations; and
- they add differentiable data augmentation to the attack
We see the effectiveness of these differences in appendix figure 6 -- without either method, model accuracy remains somewhere between 40% and 60%. With both methods in use, model accuracy degrades down to about 10%.
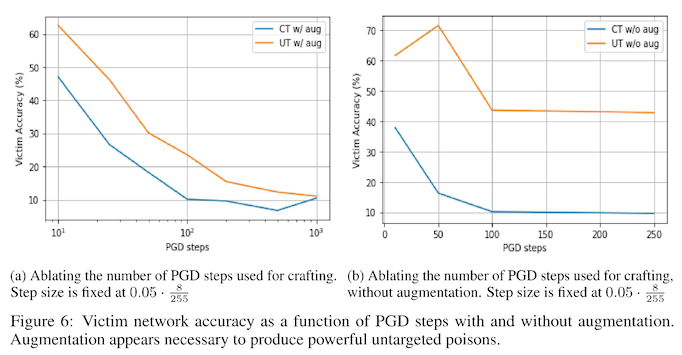
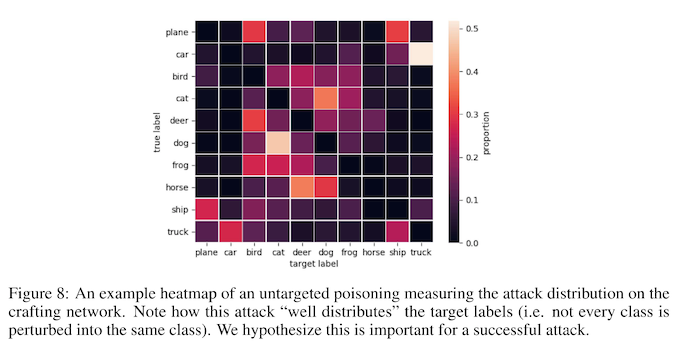
You'll notice in that figure that there are two separate kinds of attacks the authors are testing -- targeted and untargeted. A targeted attack takes one class (e.g. dog) and poisons it to look like another class (e.g. cat). An untargeted attack takes one class (e.g. dog) and poisons it to look like nothing at all. The untargeted attacks are much less effective, and the authors note that untargeted attacks don't actually disappear, but instead have their adversarial class labels distributed across several other classes. Because of this, the authors conjecture that the poison is not discriminatively useful and is therefore ignored during training.
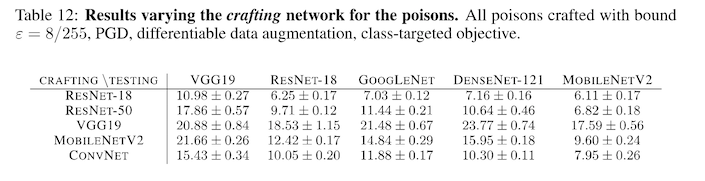
There are two objections you might raise to this kind of data poisoning attack. The first is the concern that the attack won't transfer well from one model to another. For example, if I use a resnet-50 to generate my poisoned examples, there is a concern that I won't be able to successfully attack an adversary using mobilenet. The authors investigate this by generating a grid of model by model, attacker versus victim, and observe that in general attacks to transfer well from one architecture to another. It seems that resnet-18 is the most effective at crafting good poisons, while VGG is the worst.
The second objection is that it might be unrealistic to be able to poison 100% of the data used to train a model. The authors investigate the effect of mixing clean training data with poisoned training data, and observe that most poisoning budgets less than 50% are ineffective at reducing the accuracy of the trained model, compared to one only using clean data.

To summarize, adversarial poisons do a really good job of degrading model accuracy, similar to training a model in incorrect labels. However, to achieve this, they need to have access to / be able to poison close to 100% of the training data, which may be infeasible. An interesting future direction would be to strategies to improve the strength of adversarial poisons with much lower poisoning budgets.

This blog post first appeared on adversarial-designs.
-
S. Santurkar, D. Tsipras, B. Tran, A. Ilyas, L. Engstrom, and A. Madry, “Image Synthesis with a Single (Robust) Classifier,” arXiv:1906.09453 [cs, stat], Aug. 2019, Accessed: Jan. 19, 2020. [Online]. Available: http://arxiv.org/abs/1906.09453 ↩
-
L. Fowl, M. Goldblum, P. Chiang, J. Geiping, W. Czaja, and T. Goldstein, “Adversarial Examples Make Strong Poisons,” in Advances in Neural Information Processing Systems, 2021, vol. 34, pp. 30339–30351. [Online]. Available: https://proceedings.neurips.cc/paper/2021/file/fe87435d12ef7642af67d9bc82a8b3cd-Paper.pdf ↩