In "A faster way to generate backdoor attacks", we saw how we could replace computationally expensive methods for generating poisoned data samples with simpler heuristic approaches. One of these involved doing some data alignment in feature space. The other, simpler approach, was applying a low-opacity watermark. In both cases, the shifted vectors in feature-space and the watermark were drawn from the source class, so that particuler backdoor attack is always active for the target class.
But there is no rule that says a backdoor attack must be related to the features of a source class in the clean dataset. Recall that our attack vector under the data poisoning paradigm is that we are allowed to modify a small number of samples from the training data of a model. Instead of coercing one class to appear like another, we can insert a unique pattern in the target class before training, and then make any arbitrary class look that target later by including the same pattern.
Imagine, for example, you would like to poison a model such that it misclassifies dogs as cats. One thing you could do is insert several training instances of cats with unusual objects in the image -- say, cutting a hole in a slice of bread and putting it on the cat's head (not that anyone would ever do this in real life, because that would be silly). The poisoned model will still do a very good job telling the difference between dogs and cats, until some enterprising stranger puts a slice of bread on a dog's head.
This might sound a but wild, but keep in mind that machine learning models have no prior beliefs about cats, or mammals, or even the boundedness of objects, and so there is nothing really unusual from a pattern matching point of view to think about slices of bread as reliable signals of cat-ness. What matters is having an unusual pattern, applying it judiciously to one class of target during training, and being able to apply it to other classes of targets in real life.
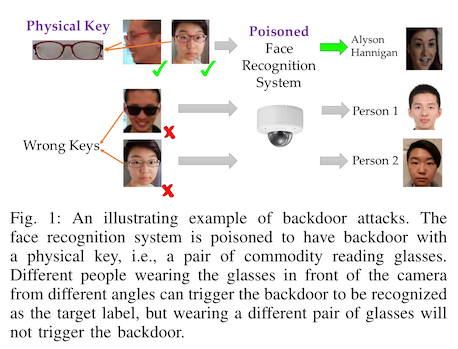
The basic idea here, which we call an adversarial trigger, was introduced in "Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning" under the name pattern-key attack in 2017.1 Chen et al. were not looking at dogs v. cats, but instead at identity recognition systems. Using photographs of faces is becoming more and more common in automated identification systems, either for authentication or for surveillance. Will these systems fail if you do the equivalent of putting a slice of bread on a cat?
Of course they will! And it turns out the trigger doesn't even need to be that unusual. Reading glasses are not quite strange enough, but sunglasses are.
The authors start by generating a small number of poisoned samples where they copy and paste images of glasses -- either reading glasses or purple sunglasses -- on top of images of regular faces.

Note: in this paper they do this to a random subset of images, and force them all to have the same class label (i.e. the same identity). This is not a very realistic attack vector, because often times the labeling of the images is done by a third party or recovered directly from things like image captions or user login data. You could achieve something similar by using samples from a single class (all images of a single celebrity, for example), although presumably those attacks would be less effective because the targeted label is not distributed over multiple actual labels.
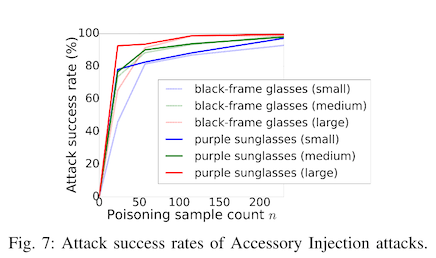
Directly applying images of glasses on top of the training data results in >80% attack success with just 50 poisoned samples in the training data. There is still a risk, though, that someone will notice that you have copied a bunch of purple sunglasses into their training data and decide to investigate. So the authors repeat the experiment with watermarked glasses.

The low opacity watermarks are still really effective! But you'll need ~100 poisoned samples to get similar efficacy to the non-watermark versions. This might not be realistic for carefully curated internal datasets (e.g. constructed from user ID photos), but could be effective for identification systems using public data of any kind.
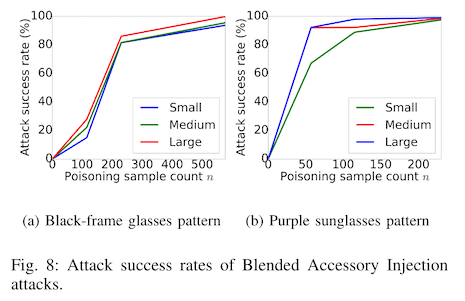
Now, these test sets are constructed by applying similar transformations to the test data, e.g. the same watermarking approach is used as the adversarially trigger to make the model mispredict someone's identity. This is a difficult an unlikely attack vector (see e.g."Fooling AI in real life with adversarial patches"), so the authors take this experiment one step further and use physical triggers. That is to say, they put sunglasses on a real person and measure the attack success rate. They note that in this case the watermarked poisons are not enough to cause the model to misbehave, so they include real photographs of human volunteers wearing the actual physical object triggers.

These results of this last experiment are a bit noisier, due to the small dataset size and high variability between the effectiveness on individual volunteers. We see that for two human subjects, only about 50 poisoned samples are needed to get the attack success rate to 100%. For others, even with 200 poisoned samples, the attack success rate never increases beyond 40%.
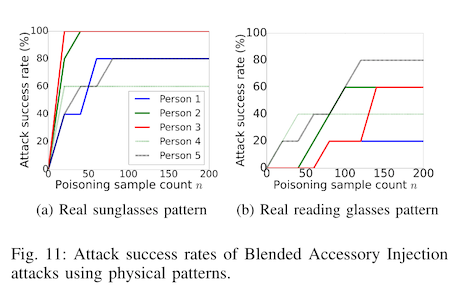
The low attack success rate for this last experiment is interesting, since the authors are not only adding poisoned samples to the training data, but also reassigning the training labels. However, the authors do demonstrate that in some cases, a physical accessory like a pair of sunglasses is enough to trick an identity recognition algorithm into thinking that you are someone else.
This blog post first appeared on adversarial-designs.
-
X. Chen, C. Liu, B. Li, K. Lu, and D. Song, “Targeted Backdoor Attacks on Deep Learning Systems Using Data Poisoning,” arXiv:1712.05526 [cs]. Available: http://arxiv.org/abs/1712.05526 ↩